Speech Enhancement using Deep Learning 2/? - Further Concepts
Goal and rationale
In the previous post on this project, we did some heavy lifting to motivate and understand the ingenious Discrete Fourier Transform (DFT), to show that we can decompose a time-domain signal into its frequency components by making use of some clever math. In this sequel, I want to extend our understanding of the DFT by introducing some concepts that are crucial for understanding how to use it in practice, including spectral leakage, windowing, the Short-Time Fourier Transform (STFT), and - of course - the inverse DFT.
Analysis frequencies
Let’s recall the DFT formula from the last post. For a real-valued, discrete signal of length , the DFT is defined as
In the previous post, we showed that the DFT is able to decompose the signal into its frequency components, by analyzing how much of a certain frequency is in our signal. Crucially, is given is cycles / signal-duration, or
where is the duration of the signal in seconds. To give an example, we can look at the signal from our previous post, which had a length of exactly 1 second. Therefore, all -values correspond neatly to the integer equivalents.
In general, all frequencies
are called our analysis frequencies, as they represent the frequencies we can unequivocally identify from our signal, of course only up to the Nyquist frequency, otherwise aliasing occurs.
If we look back at our magnitude plot, we observe that we have a neat peak at exactly , while it being zero everywhere else. From what we learned this makes sense, as one of the analysis frequencies of our DFT exactly matches the frequency of our signal ().
But what happens if this is not the case?
Spectral leakage
Consider the following two signals, of which one is our original signal (blue), and the other is a signal (orange). They are both sampled at for :
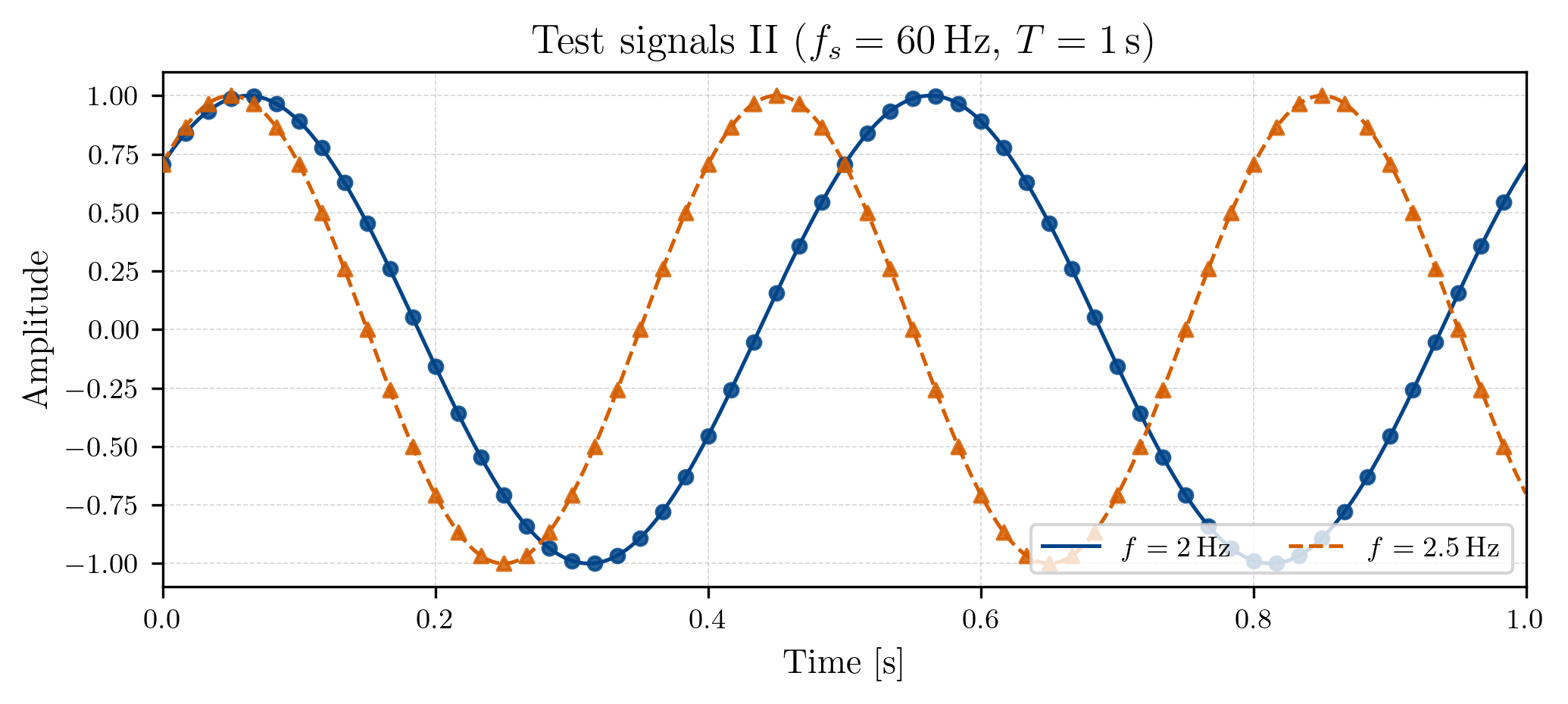
From this image and what we figured out so far, we can make two crucial observations.
-
is not an analysis frequency of our DFT () which are given by integer multiples of for .
-
The signal does not complete an integer number of cycles within the 1 second duration of our signal, while the signal does.
In fact, both of these observations are just two different ways of saying the same thing. If a signal completes an integer number of cycles within the duration of our signal, then it will always be an analysis frequency of our DFT (again, which we can only sensibly identify up to the Nyquist frequency), and vice versa.
We will now see that if a signal does not complete an integer number of cycles within the duration of our signal, the energy of that signal will “smear” across all frequencies in the DFT, instead of being concentrated at a single frequency bin. This phenomenon is called spectral leakage and looks like this in the spectrum:
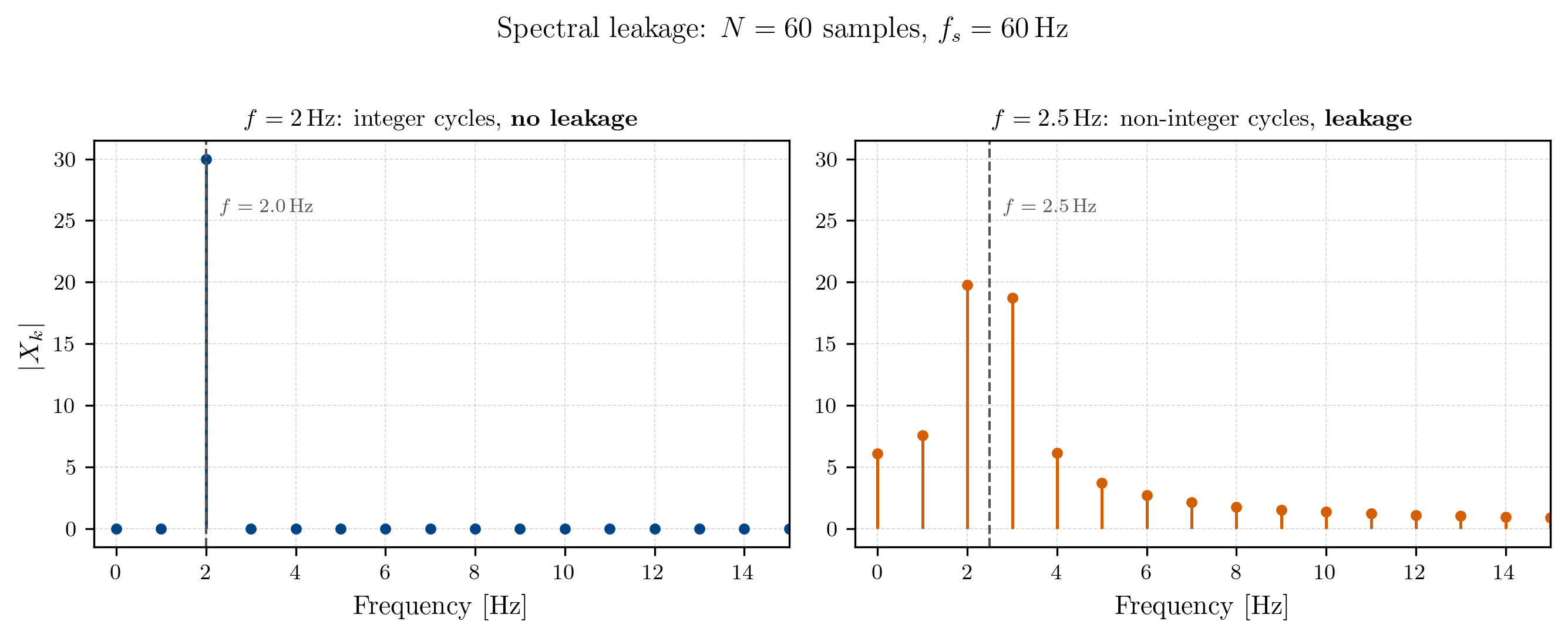
Why exactly this happens is relatively straightforward to show, but involves a bit of math. If you just want to know what we can do to avoid or at least mitigate spectral leakage, you can skip the next part and jump to the section on windowing.
Spectral leakage as a consequence of the DFT’s implicit rectangular window
One way to understand spectral leakage is to imagine our signal as a cut-out of an infinite, continuous signal. Therefore, let be our (continuous) signal, the “cut-out function”, which in signal processing usually is called the window function. To get the cut-out signal we want, our window function has to be the rectangle function, that has a value of 1 where our target part of the signal is, and 0 everywhere else. In gneneral, the rectangle function is defined as:
The idea of our proof, revolves around the convolution theorem of the Fourier analysis, stating that the Fourier transform of a product of two functions is equal to the convolution of their Fourier transforms. Formally,
where is the Fourier transform, and are the Fourier transforms of and respectively, and is the convolution operator. A consequence of this is, that multiplication of two functions in the time domain corresponds to convolution of their Fourier transforms in the frequency domain:
Now, what we hope to prove here is, that when we convolve the transform of our signal with the transform of the rectangular window function, we will be able to see how the spectral leakage arises out of it. Great, so let’s make plan:
- Calculate the Fourier transform of our signal
- Calculate the Fourier transform of the rectangular window function
- Convolve the two, and see how this affects our spectrum
First, we define our signal, and also convert it to complex exponential form to ease later calculation.
where will be the in our example. The standard definition of the continuous-time (we will go back to discrete-time very soon) Fourier transform is
Replacing with our signal and integrating gives us
Given the definition of the Dirac delta function
we can replace the integrals in (1) with delta functions, by setting in the first part and in the second part, which gives us
For our signal,
meaning that all the energy of our signal is concentrated at and (the negative frequency component is just a mathematical artifact of our complex exponential representation of the signal, and does not have a physical meaning in our case).
For the rectangular window function, we can calculate its Fourier transform as follows:
As we can see, the Fourier transform of the rectangular window function is the normalized sinc function which looks like this:
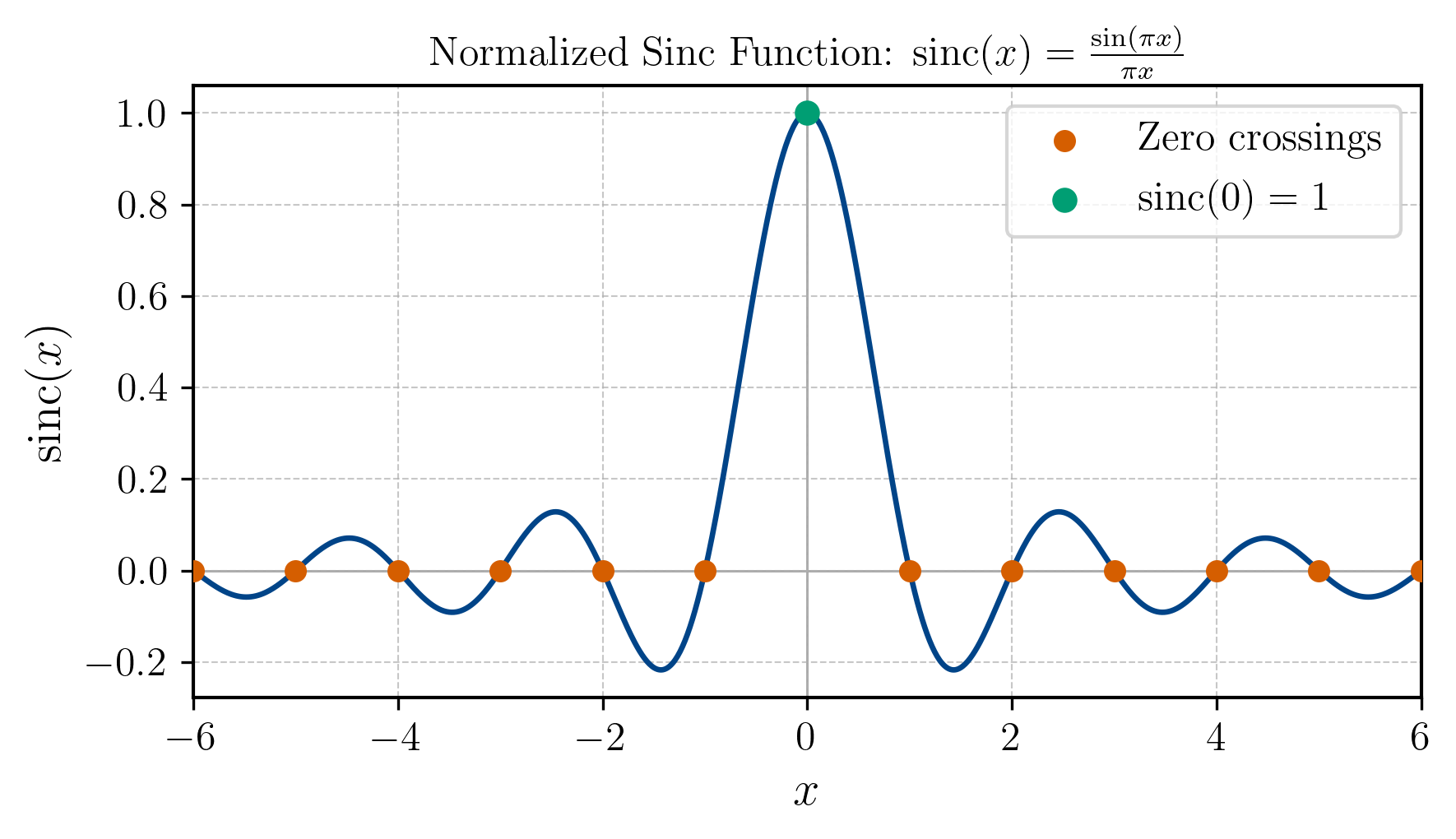
The only thing left to do now, is to convolve with . The formal definition of convolution is
For our case, let us only look at the positive frequency part of , as the negative frequency part is just a mirror image of it.
The sampling property of the delta function arises from the fact that the delta function is zero everywhere except at the point where its argument is zero, where it is infinite, while its integral over the entire real line still is equal to 1. Therefore, when we integrate a function multiplied by a delta function, we are essentially “sampling”, or “pulling out” the function value at the point where the delta function is non-zero.
The only thing left to do now, is to look at the magnitude of our spectrum, which is given by
Okay, that was a lot of math, so let us take a step back and remind ourselves of the bigger picture. All we wanted was to show, why a signal that does not complete an integer number of cycles within the duration of our signal, has a smeared spectrum across all frequencies, while a signal that does complete an integer number of cycles has a neat peak at its frequency. If you perform the same convolution for the signal, we will see that its spectrum is the same sinc function, but centered at instead of .
Let’s plot both of these spectra together (and drop the constant of the sinc for better visualization):
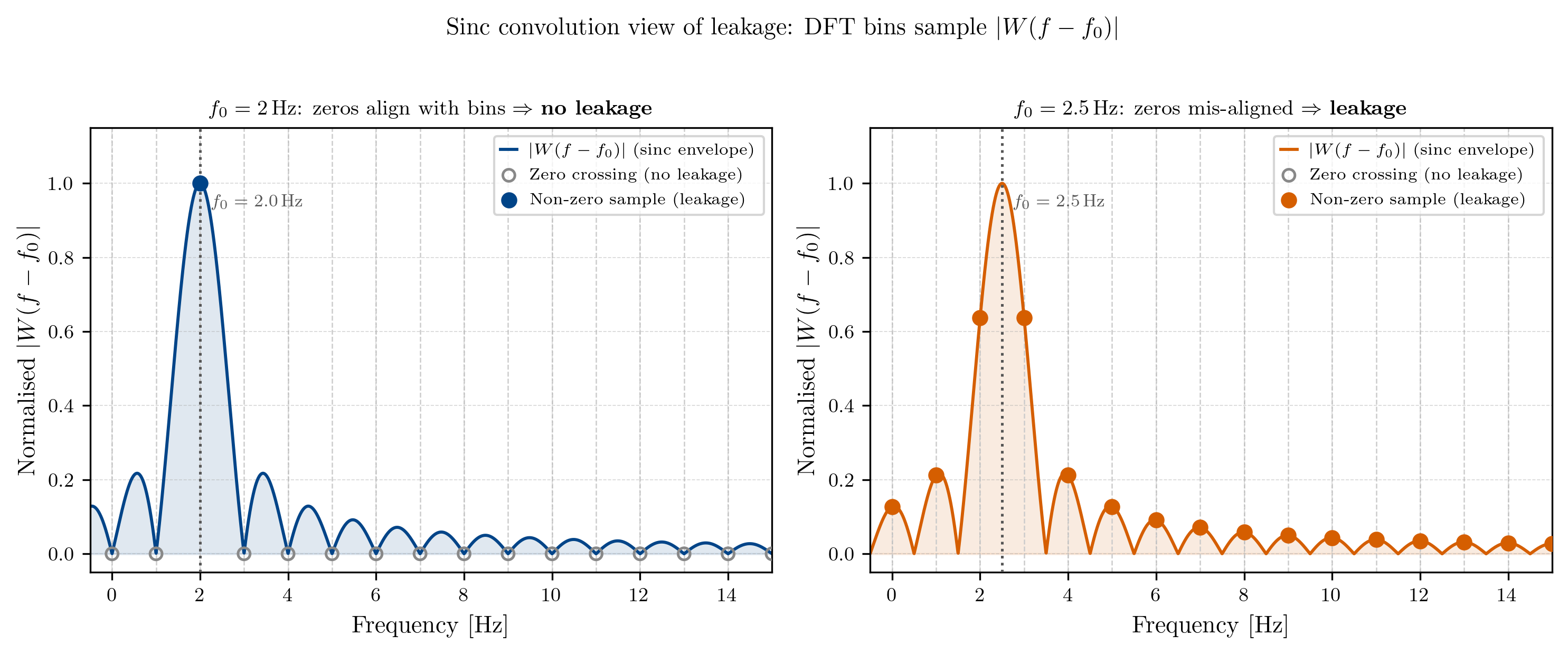
Now, here is the crucial part. In our discrete case, we only have access to the values of the spectrum at the analysis frequencies, which are given by integer multiples of , or in our example at integer frequencies. Further, for the sinc function it holds that . In the figure above, we can see that for our signal, all analysis frequencies except for are located at the zero-crossings of the sinc function, meaning that we will only see a peak at in our spectrum. For our signal however, all analysis frequencies are located at points where the sinc function has non-zero values, meaning that we will see energy at all frequencies in our spectrum, which is exactly what we observed in Fig. 2 .
Windowing
Obviously, spectral leakage is not a desirable phenomenon, and to make matters worse, it cannot be avoided in general, as “the energy in a signal associated with each frequency has to go somewhere in the DFT, and if the frequency does not correspond to one of our analysis frequencies, then it will spread out.” - Brian McFee.
The good news is, that we can control the magnitude of the leakage by a technique called windowing.
In the previous section, we showed that the leakage mathematically arises, because our signal has to be interpreted as a finite-time cut-out of an infinite signal. To arrive at a signal that that is zero everywhere, except where we observe it, we set the “cut-out function” to be the rectangle function that is 1 where our target part of the signal is, and 0 everywhere else. However, exactly the choice of causes all of the leakage.
The general idea is, to multiply our signal by a different window function than the rectangle, such that we force all frequencies to perform an integer amount of cycles. The standard way to do this is to force the signal to smoothly approach . This results in a windowed DFT :
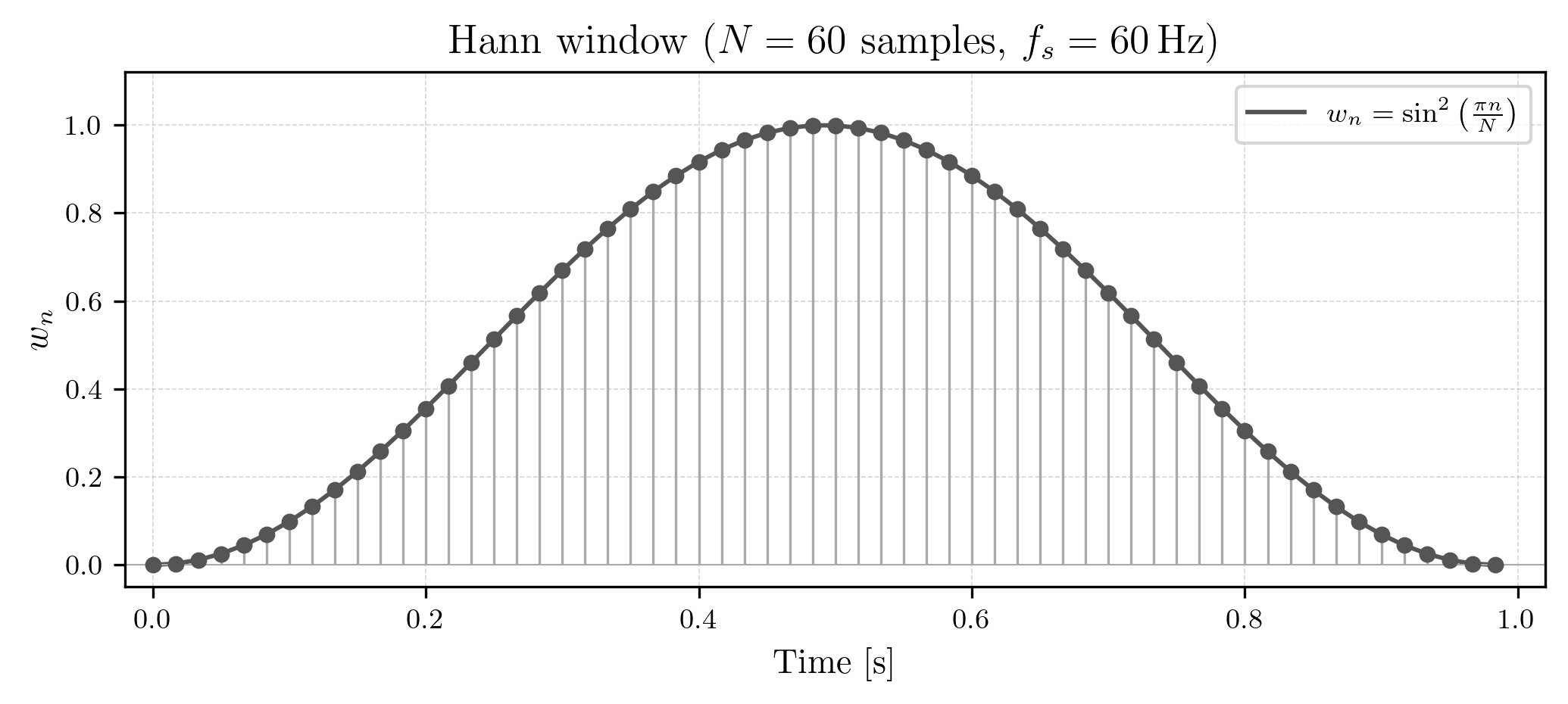
where is a discrete window function. A very common choice for is the Hann window, which is defined as
and for our example looks like this:
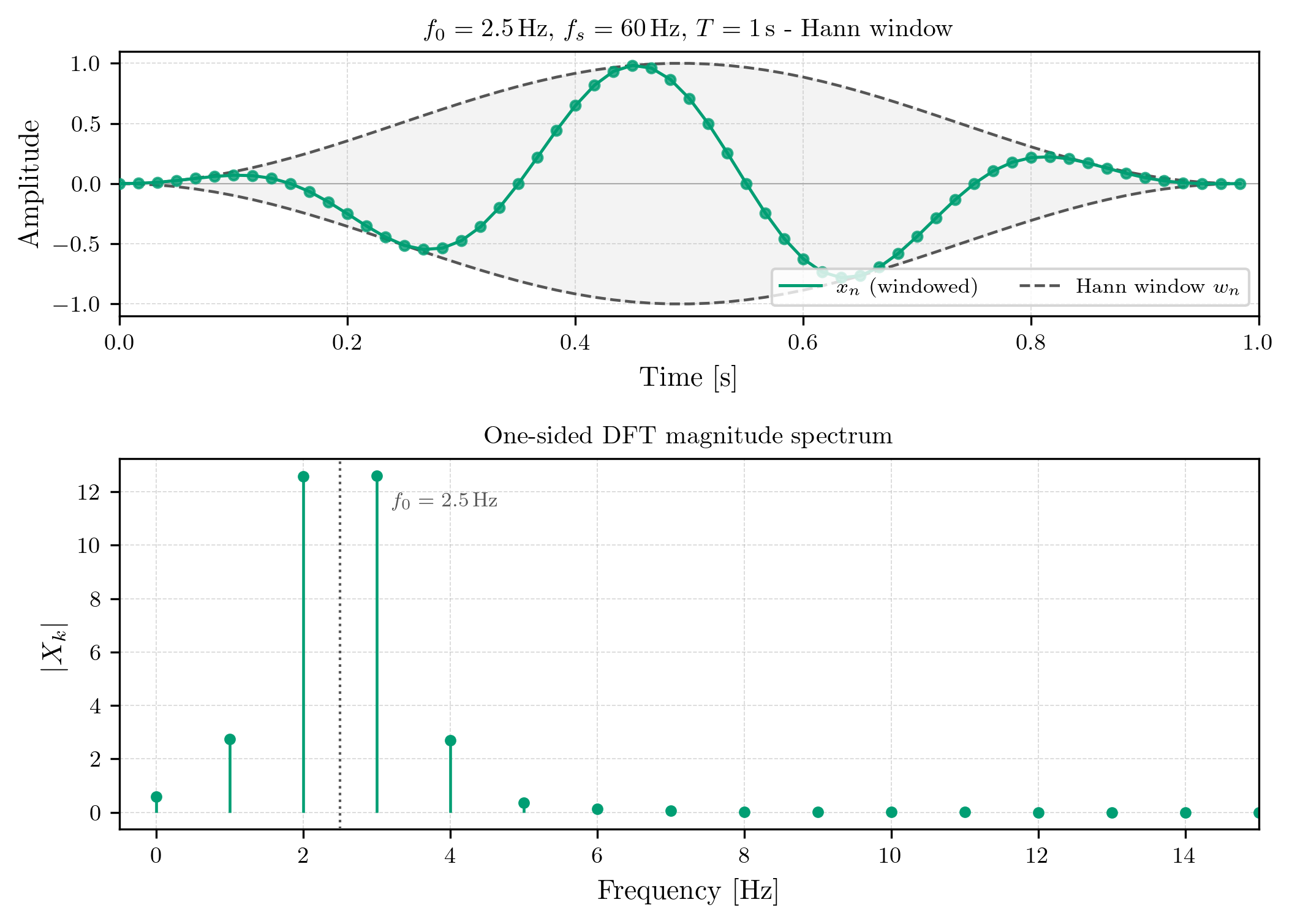
If we now were to apply the Fourier transform to our signal after applying the Hann window, we can observe that the spectral leakage is significantly reduced, as the energy of our signal is now more concentrated around its true frequency,
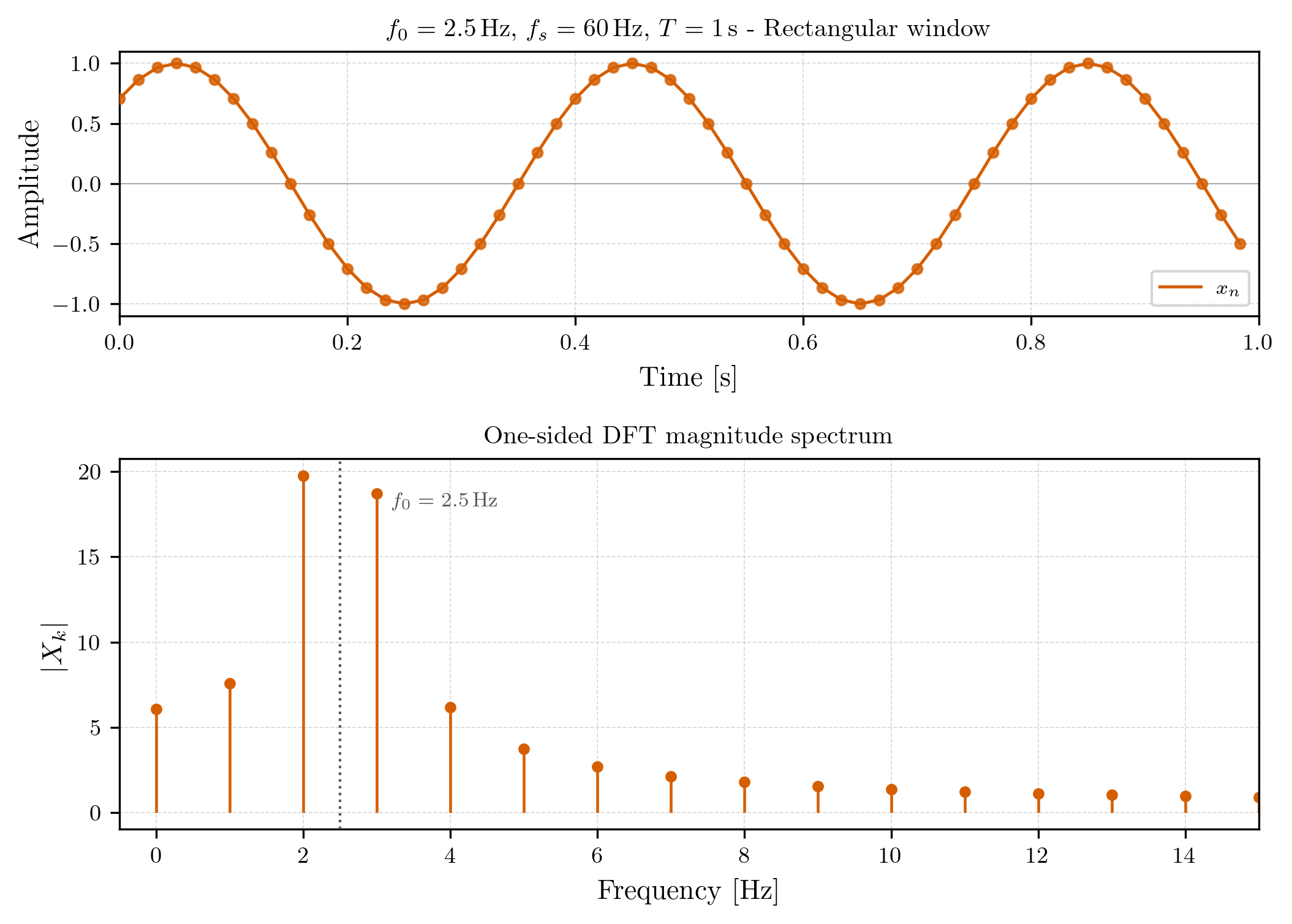
compared to the rectangular window case:
The Hann window is just one of many different proposed window functions. You can find a longer list of functions on the Wikipedia and a more detailed discussion of their properties in McFee’s chapter on it.
In conclusion:
-
Spectral leakage is an inherent, and unavoidable phenomenon of the DFT, arising from the fact that we are analyzing a finite-time, cut-out of an infinite signal, using an implicit rectangular window function. In case this cut-out does not contain an integer number of cycles of a certain frequency, the energy of that frequency will be smeared across all frequencies in the DFT, instead of being concentrated at a single frequency bin.
-
We can control the magnitude of the leakage by applying a window function, different from the implicit rectangular window, to our signal before applying the DFT. There exist many different window functions, but the Hann window is a general-purpose-choice for many signal processing applications.
The Short-Time Fourier Transform (STFT)
The techniques we have discussed so far, allow us to transform a signal from the time domain to the frequency domain, where we can inspect the magitudes of the frequencies building our signal. What our current knowledge does not allow us to do, however, is to see how the frequencies of a signal change with time. If we remember the footsteps signal from the first part, we would expect there to be lower and louder frequencies when the foot touches the floor, and higher and more quiet ones when the foot is moving. To do this, we use the concept of the STFT, and it’s straight forward to grasp.
In principle the STFT does nothing more than to apply the DFT to small chunks of our signal, so that we get a spectrum for each one. We can then view these resulting spectra over time, to actually see our frequencies evolve. Formally:
Here, is a window function, which we apply to each chunk of our signal, to mitigate spectral leakage. The parameter is the hop size, which determines how much we shift our window for each chunk. is the window length, and is the number of chunks. For example, if we have a signal of length 1000, and we choose and , we will get spectra for the following chunks of our signal: , , , and so on.
The formula may look a bit intimidating at first, but it is really just a straightforward extension of the DFT formula we already know, with the addition of the window function and the hop size. The resulting STFT is a 2D matrix, where each column corresponds to the spectrum of a chunk of our signal, and each row corresponds to a frequency bin. We can visualize this matrix as a spectrogram, which is a heatmap of the magnitudes of the frequencies over time.
Let’s look at an example of a spectrogram of our footstep signal. Let’s go with some arbitrary parameters. We will use a window length of samples, a hop size of samples, and a Hann window:
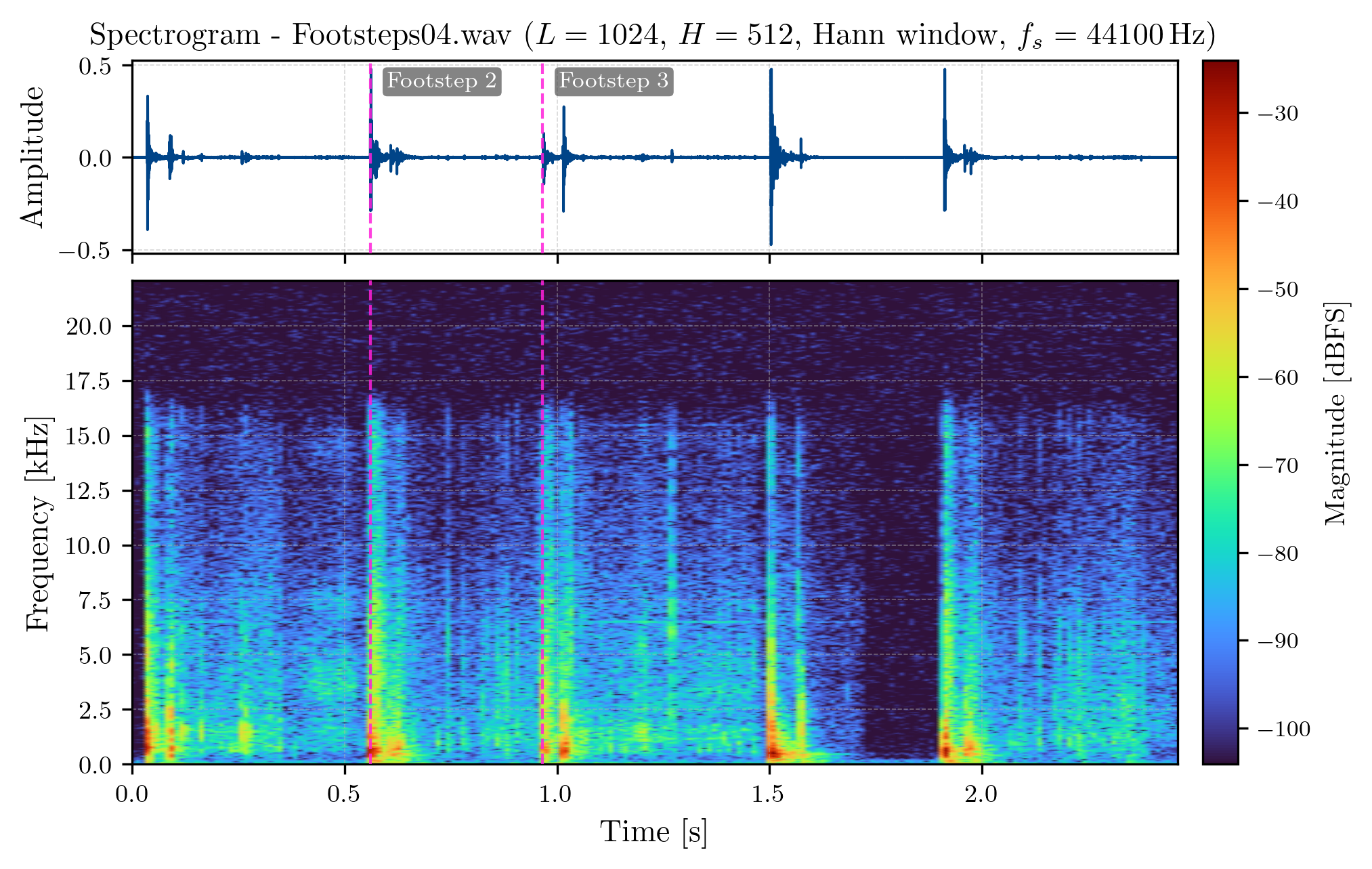
The bottom part of the figure above shows the spectrogram of our footstep signal, with the magnitues in full-scale decibels . We read this spectrum relatively intuitively as follows: the x-axis corresponds to time, and the y-axis corresponds to frequency. The color of each point in the spectrogram corresponds to the magnitude of that frequency at that time, with brighter colors indicating higher magnitudes. The two vertical lines in the spectrogram correspond to two selected footstep events. As proposed earlier, we can indeed see that there are higher and more quiet frequencies when the foot is moving, and lower and louder frequencies when the foot touches the floor.
As with every topic we discuss in this series, there is a lot more to say about the STFT, but one concept in particular I want to cover, as it fundametally limits how accurate the STFT can get: the Gabor Limit.
The Gabor Limit is basically the uncertainty principle of signal processing, stating that there is a trade-off between the time resolution and the frequency resolution of the STFT. In other words, if we want to have a high time resolution (i.e., be able to see how frequencies change very quickly), we have to use a short window length , which will result in a low frequency resolution (i.e., we won’t be able to distinguish between closely spaced frequencies). Conversely, if we want to have a high frequency resolution, we have to use a long window length, which will result in a low time resolution. We can easily show this with an example. Consider a signal that is sampled at and has a duration of . If we choose a window length of samples, we will get a frequency resolution of , meaning that we can distinguish between frequencies that are at least apart. However, if we choose a window length of samples, we will get a frequency resolution of , meaning that we can only distinguish between frequencies that are at least apart. This trade-off is a fundamental limitation of the STFT, and it is important to keep it in mind when choosing the parameters for our speech enhancement model later.
The Inverse DFT
So far, we have only been moving from the time domain into the frequency domain. The Inverse DFT (IDFT) does exactly the opposite: given a spectrum , it reconstructs the original time-domain signal . The intuition is simple - instead of decomposing a signal into complex sinusoids by projecting onto them, we sum those sinusoids back up, each weighted by its corresponding frequency-domain coefficient:
Comparing this with the DFT formula, the only differences are the sign in the exponent (now positive) and the normalization factor . Together, these two operations form a perfect pair: apply the DFT to go to the frequency domain, manipulate the spectrum as desired, then apply the IDFT to return to the time domain. This round-trip property makes the IDFT the essential ingredient in any speech enhancement pipeline: after we have estimated which parts of the spectrum belong to noise, we can suppress them and reconstruct a clean signal.
Summary
In this post, we extended our understanding of the DFT with four key concepts that are essential for applying it in practice:
-
Analysis frequencies: the DFT does not give us a continuous spectrum, but rather evaluates it at a discrete set of frequencies for . Only signals whose frequency coincides with one of these analysis frequencies are represented cleanly.
-
Spectral leakage: when a signal does not complete an integer number of cycles within the observation window, its energy smears across all frequency bins. This is an inherent consequence of implicitly multiplying the signal by a rectangular window, whose Fourier transform is the sinc function. Convolution of the signal’s spectrum with this sinc function is what produces the leakage.
-
Windowing: by replacing the implicit rectangular window with a smoother alternative (such as the Hann window), we can force the signal to taper smoothly to zero at both ends. This significantly reduces the magnitude of the leakage, at the cost of a slightly wider main lobe.
-
The STFT: to track how frequencies evolve over time, we slide a window across the signal and apply the DFT to each overlapping chunk. The result is a 2D time-frequency representation called a spectrogram. The Gabor Limit tells us that there is an unavoidable trade-off between time resolution and frequency resolution: a shorter window gives better time resolution but coarser frequency bins, and vice versa.
-
The Inverse DFT: the IDFT inverts the DFT by summing the complex sinusoids back up, each weighted by its spectral coefficient. Together, the DFT and IDFT form a lossless round-trip between the time and frequency domains, which is the cornerstone of the speech enhancement workflow we will build in the next posts.
Perfect! In the next post, we will finally start building our first model, the “denoising autoencoder”, where all the concepts we have covered so far and even more will come together in a beautiful way. See you in the next one!
Literature
McFee, Brian. Digital Signals Theory. Chapman and Hall/CRC, 2023.